开源项目
Logic-of-Thought: Empowering Large Language Models with Logic Programs for Solving Puzzles in Natural Language (arXiv)
09 June 2025
开源项目
大语言模型
知识表示与推理
We propose Logic-of-Thought (Logot), a novel framework that bridges LLMs with logic programming to address this problem. Our method leverages LLMs to translate puzzle rules and states into answer set programs (ASPs), the solution of which are then accurately and efficiently inferred by an ASP interpreter. This hybrid approach combines the natural language understanding of LLMs with the precise reasoning capabilities of logic programs.
[arXiv] [github]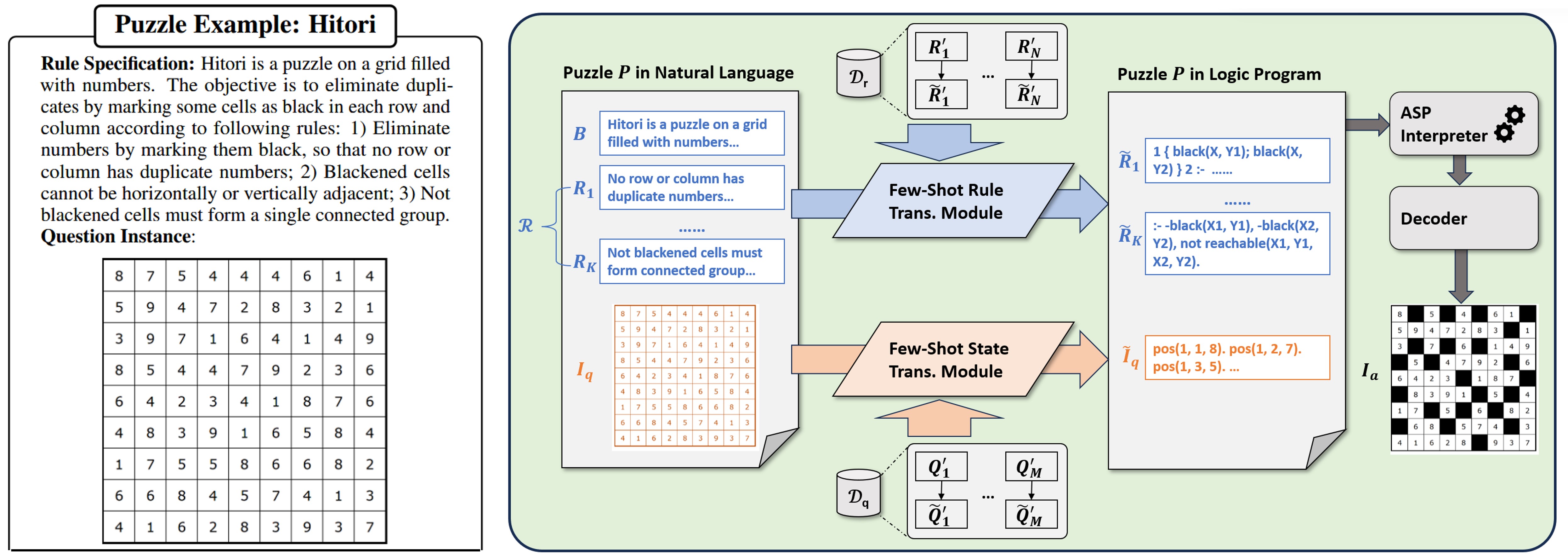
DNF: Unconditional 4D Generation with Dictionary-based Neural Fields (CVPR 2025)
01 December 2024
开源项目
3D
动画
生成
We propose DNF, a dictionary-based representation for the unconditional generation of 4D deforming shapes, with a transformer-based diffusion model. Our method is capable of generating motions with superior shape quality and temporal consistency.
[project page]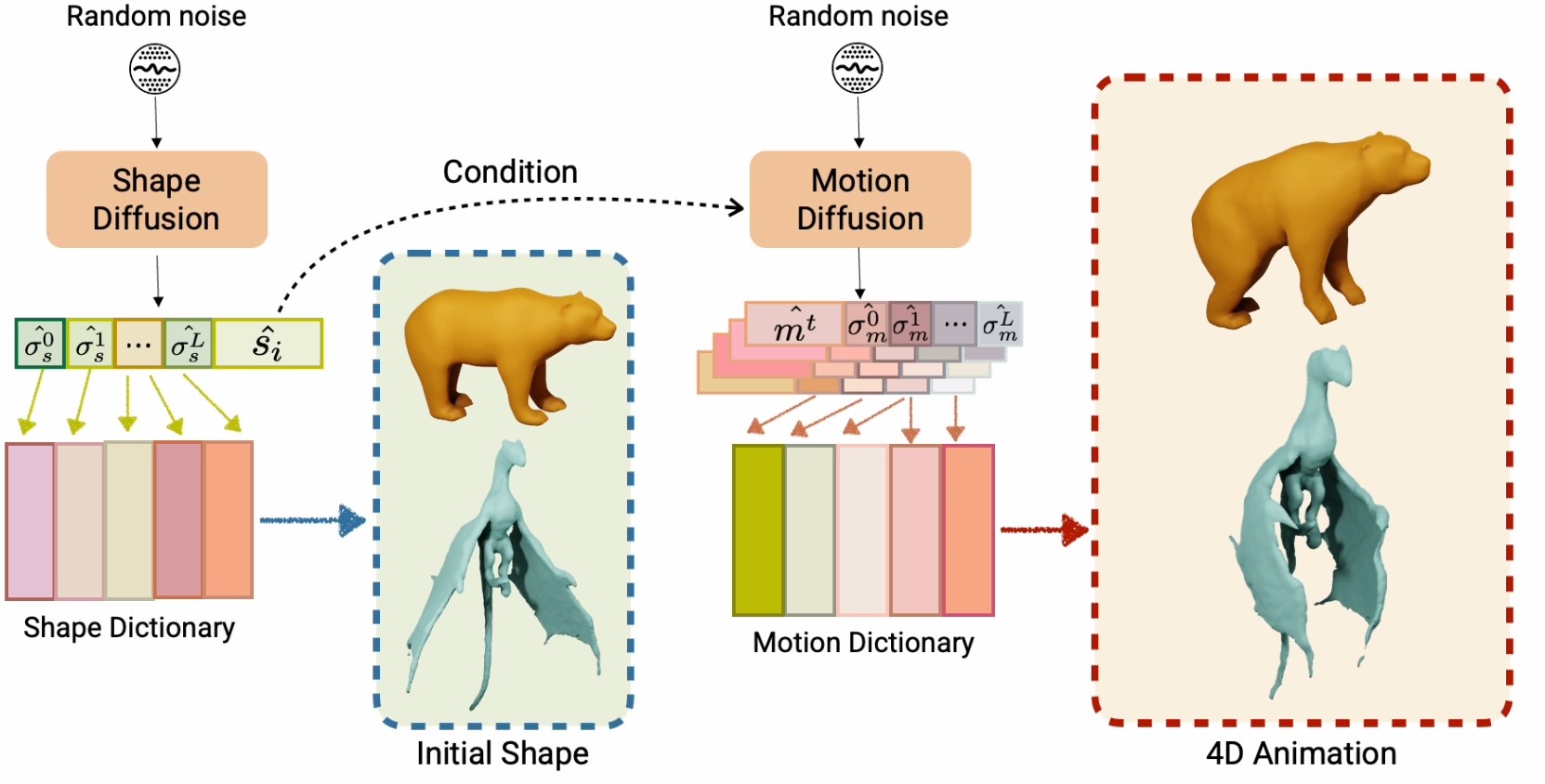
LCM: Locally Constrained Compact Point Cloud Model for Masked Point Modeling (NeurIPS 2024)
28 October 2024
开源项目
3D
点云
We propose a Locally constrained Compact point cloud Model (LCM) consisting of a locally constrained compact encoder and a locally constrained Mamba-based decoder. Our encoder replaces self-attention with our local aggregation layers to achieve an elegant balance between performance and efficiency. Considering the varying information density between masked and unmasked patches in the decoder inputs of MPM, we introduce a locally constrained Mamba-based decoder. This decoder ensures linear complexity while maximizing the perception of point cloud geometry information from unmasked patches with higher information density. Extensive experimental results show that our compact model significantly surpasses existing Transformer-based models in both performance and efficiency, especially our LCM-based Point-MAE model, compared to the Transformer-based model, achieved an improvement of 1.84%, 0.67%, and 0.60% in average accuracy on the three variants of ScanObjectNN while reducing parameters by 88% and computation by 73%.
[arXiv] [github]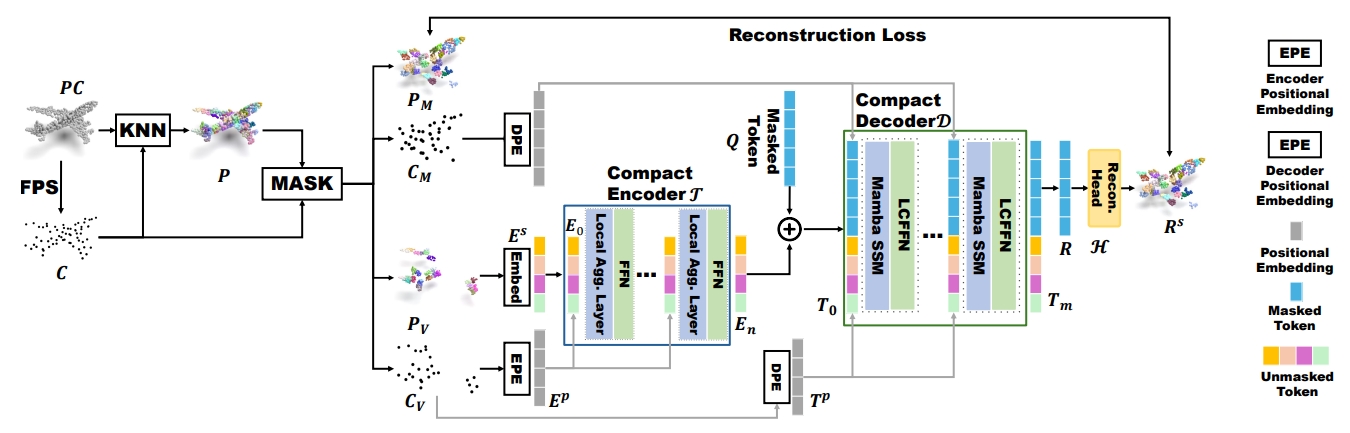
DDN: Dual-domain Dynamic Normalization for Non-stationary Time Series Forecasting (NeurIPS 2024)
17 August 2024
开源项目
时序
In this paper, we introduce a novel Dual-domain Dynamic Normalization (DDN) framework designed to address the challenge of dynamically capturing distribution variations across time and frequency domains. DDN operates in a sliding window fashion, enabling it to detect subtle, time-varying changes in data distributions. DDN performs time-domain normalization to compute local sliding statistics (mean and standard deviation) at each time step, offering a fine-grained approach compared to traditional methods that operate at a coarser level.
[github]Procedural Level Generation with Diffusion Models from a Single Example (AAAI 2024)
11 August 2024
开源项目
生成
游戏关卡
We introduce a diffusion-based generative model that learns from just one example. Our approach involves two core components: 1) an efficient yet expressive level representation, and 2) a latent denoising network with constrained receptive fields.
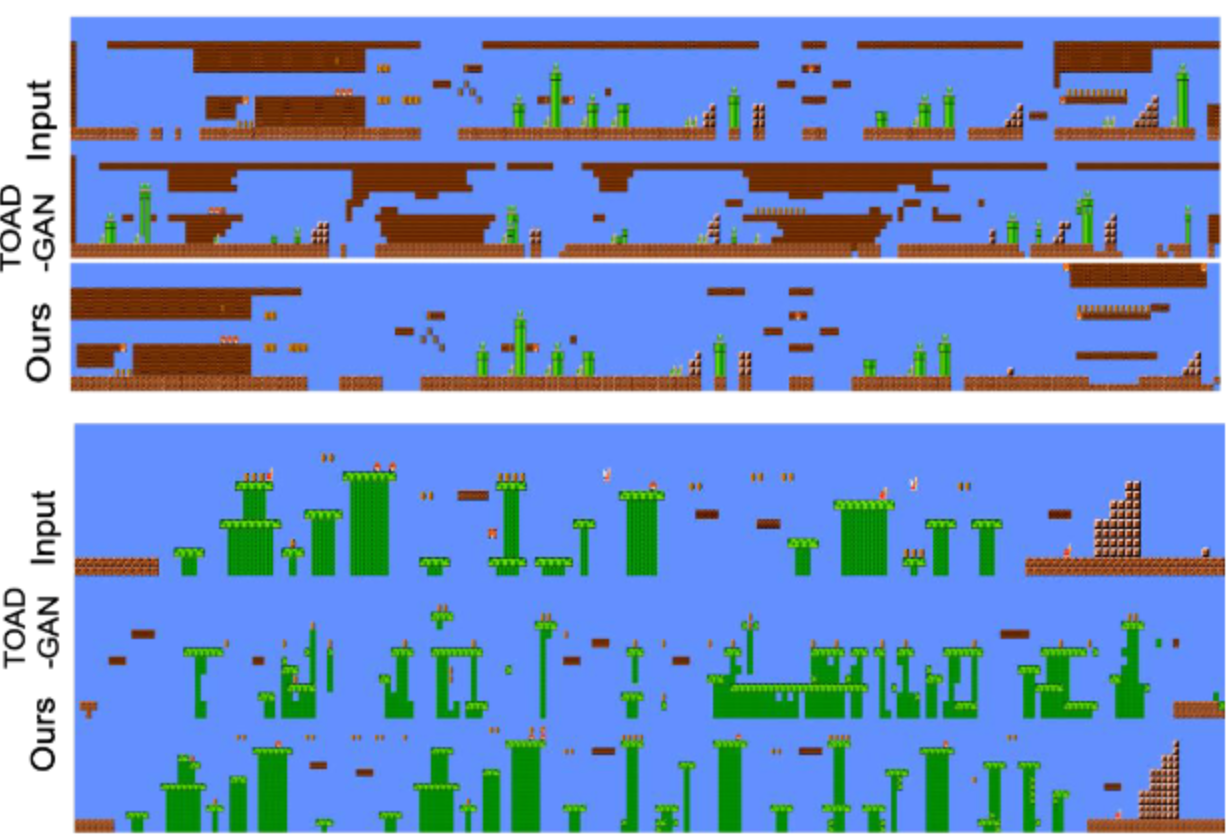
GladCoder: Stylized QR Code Generation with Grayscale-Aware Denoising Process (IJCAI 2024)
07 July 2024
开源项目
生成
二维码
In this project, we introduce a novel approach GladCoder to generate stylized QR codes that are personalized, natural, and text-driven. Its pipeline includes a Depth-guided Aesthetic QR code Generator (DAG) to improve quality of image foreground, and a GrayscaLe-Aware Denoising (GLAD) process to enhance scanning-robustness. The overall pipeline is based on diffusion models, which allow users to create stylized QR images from a textual prompt to describe the image and a textual input to be encoded.
[github]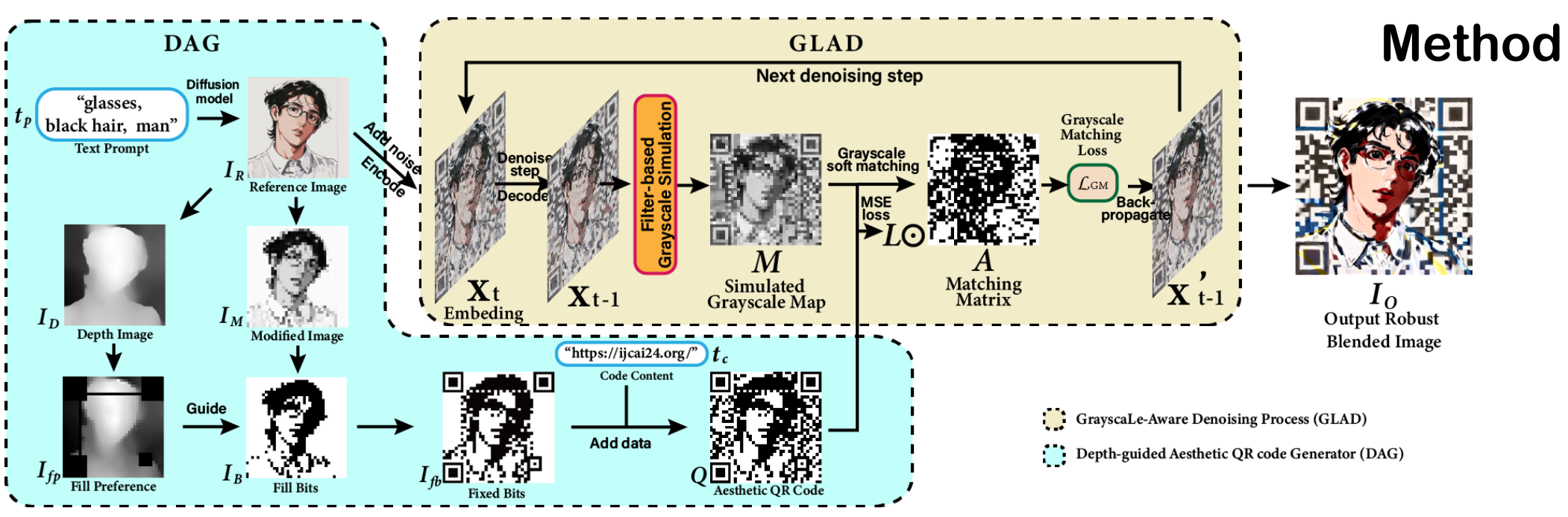
Periodicity Decoupling Framework for Long-term Series Forecasting (ICLR 2024)
24 May 2024
开源项目
时序
Quantitatively, compared with Transformer-based models, PDF (720) yields an overall 14.59% reduction in MSE and 10.77% reduction in MAE. Compared with CNN-based models, PDF (720) yields an overall 24.61% reduction in MSE and 19.91% reduction in MAE. Compared with Linear-based models, PDF (720) yields an overall 7.05% reduction in MSE and 5.51% reduction in MAE.
[github]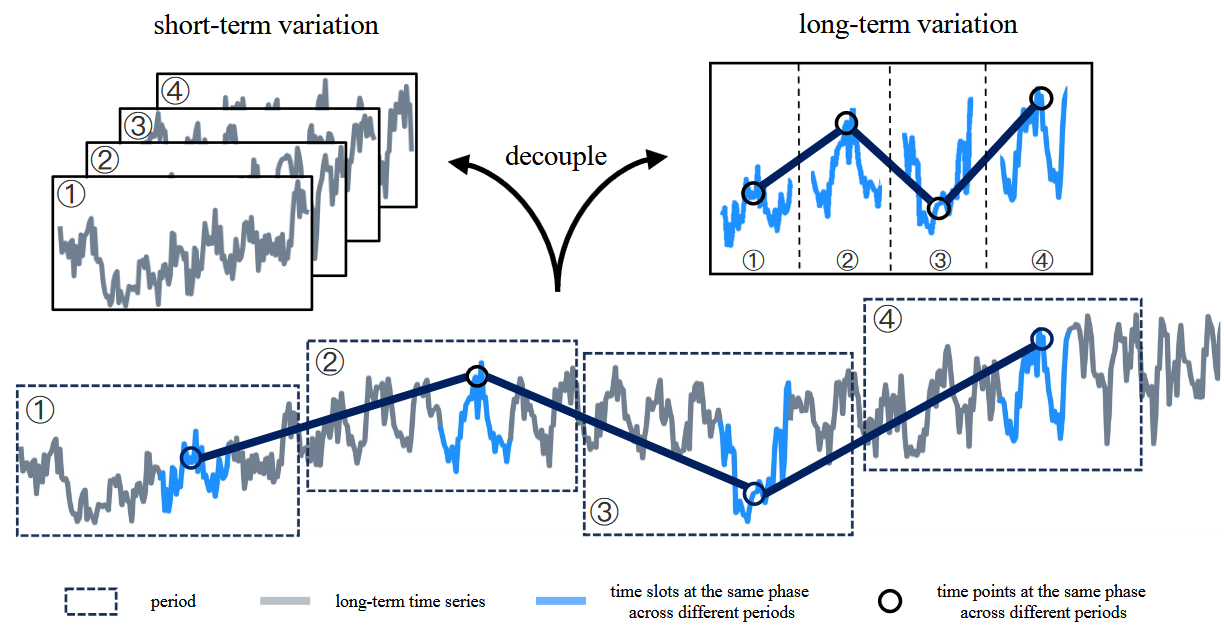
CALF: Aligning LLMs for Time Series Forecasting via Cross-modal Fine-Tuning (AAAI 2025)
23 March 2024
开源项目
时序
LLM
We propose a novel Cross-Modal LLM Fine-Tuning (CALF) framework for MTSF by reducing the distribution discrepancy between textual and temporal data, which mainly consists of the temporal target branch with temporal input and the textual source branch with aligned textual input. To reduce the distribution discrepancy, we develop the cross-modal match module to first align cross-modal input distributions. Additionally, to minimize the modality distribution gap in both feature and output spaces, feature regularization loss is developed to align the intermediate features between the two branches for better weight updates, while output consistency loss is introduced to allow the output representations of both branches to correspond effectively.
[arXiv] [github]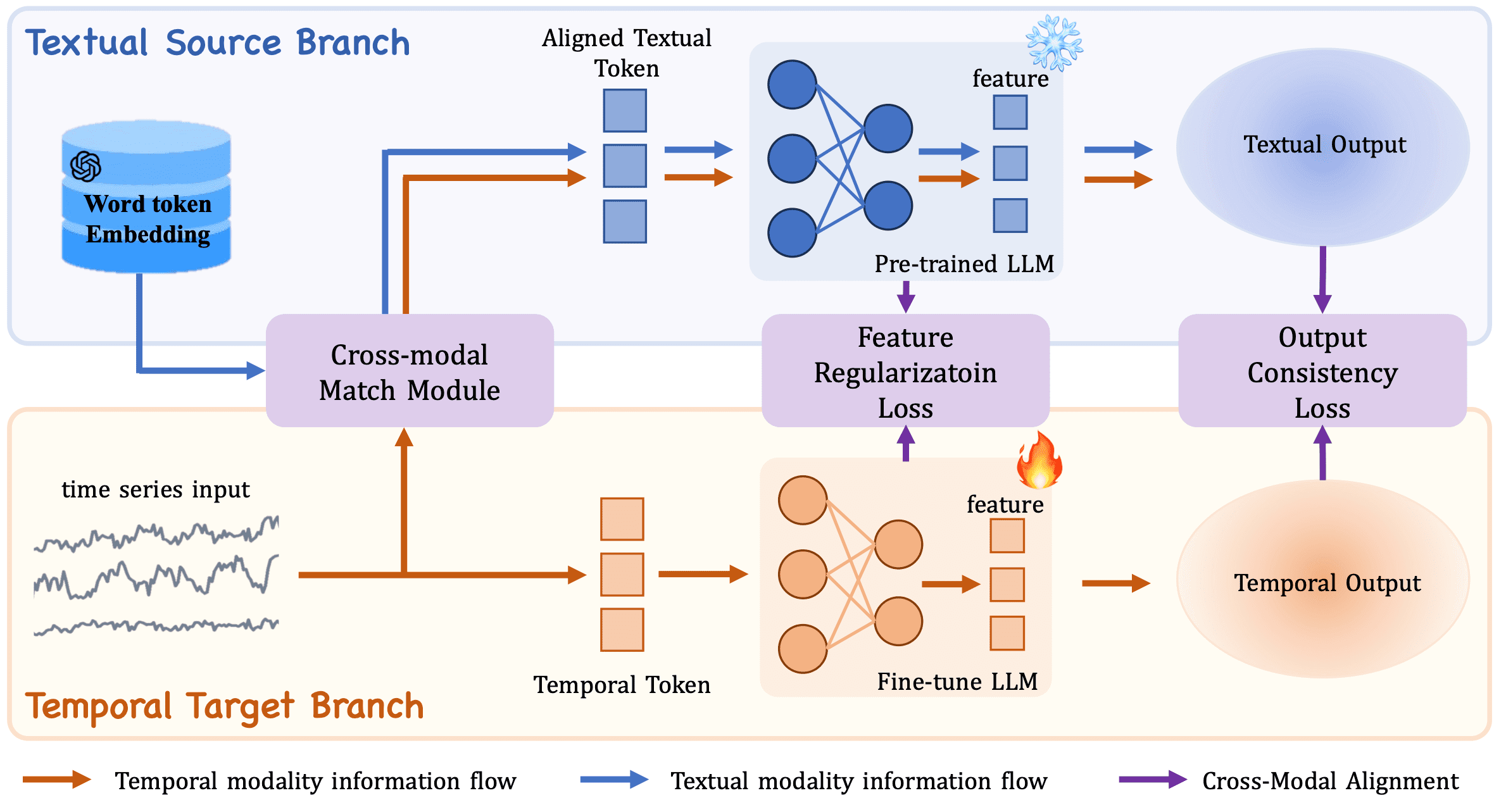
Unsupervised Surface Anomaly Detection with Diffusion Probabilistic Model (ICCV 2023)
04 October 2023
开源项目
异常检测
In this project, we propose DiffAD, a method for unsupervised anomaly detection based on the latent diffusion model, inspired by its ability to generate high-quality and diverse images. We further propose noisy condition embedding and interpolated channels to address the aforementioned challenges in the general reconstruction-based pipeline. Extensive experiments show that our method achieves state-of-the-art performance on the challenging MVTec dataset, especially in localization accuracy.
[github]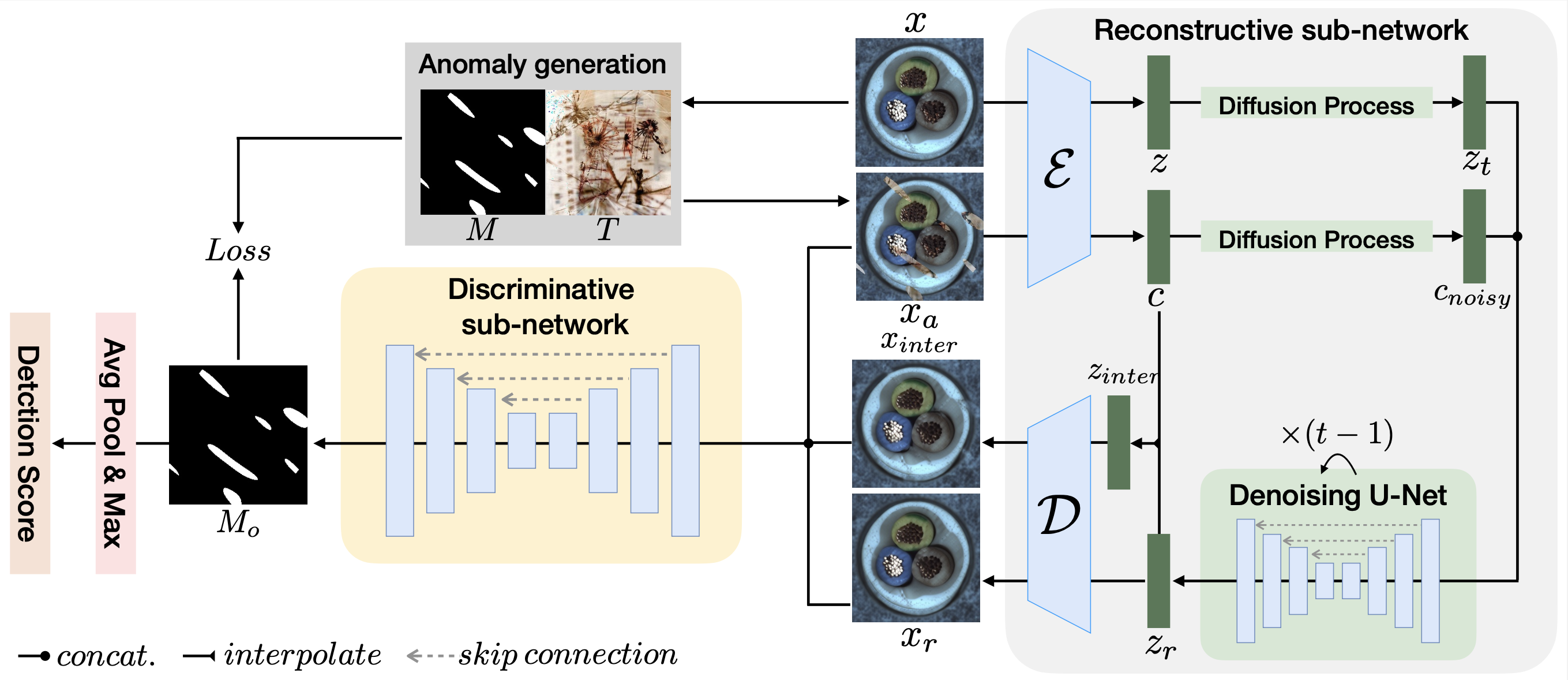

 Except where otherwise noted, this blog's content is licensed under a
Creative Commons Attribution 4.0 International License.
Except where otherwise noted, this blog's content is licensed under a
Creative Commons Attribution 4.0 International License.